TOPIC
- 機器學習有可能媽?
No Free Lunch
- Training Data訓練出來的Hypothesis g並無法準確地表達沒看過的Testing Data資料
Inference
- Statistics: Sampling(採樣)
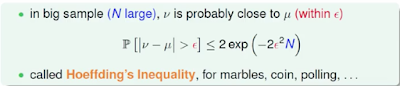
抽樣樣本數N越大,樣本的機率 v 和 真實的機率 u 誤差越小。

- 推論:找出一個差不多正確的機率分佈
- 想法:透過Hoeffding's Inequality公式中發現,真實的機率u 並不影響 樣本的機率v 是否多接近 u,換句話說我們是不需要事前知道答案的(知道也就不用算了),可以無限接近的推論出答案。(PAC -> Probably Approximately Correct)
- Verification: 即使在Training Data中 模型v 已經非常接近 真實u 了,還是無法確定 v 是否可以準確運作在真實資料u中,可以透過這個公式來驗證,P(|v-u|>0.001)<=0, N-> infinite。
Data
- E-in:
- Evaluation on training data
- E-out:
- Evaluation on un-seen data
- Good Data:
- E-in 很接近 E-out
- Bad Data:
- E-in 和 E-out 很不同,容易造成從Hypothesis set照出錯誤的 g。
- Hoeffding's Inequality:
- 評估抓出一個Bad Data的機率
Hypothesis set
- 定義:一個集合,包含各種可能的g,可以表達X->Y之間的關係。
- 課程中利用了Hoeffding's Inequality證明了如果Hypothesis set集合在"有限"數目,且資料量夠大的條件下,可以透過機器學習找出一個最好的g。

(評估找到一個Bad Data的機率 = 該資料對M個h是否為Bad Data的聯集)

Conclusion

- 如果資料分佈是有統計模型特性的,且有限可能的Hypothesis -> 可以學習的

No comments:
Post a Comment